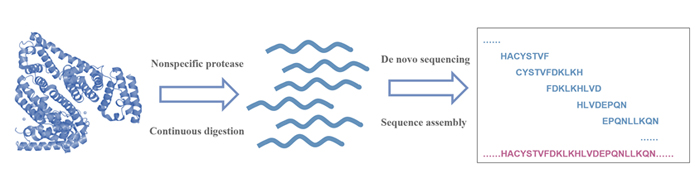
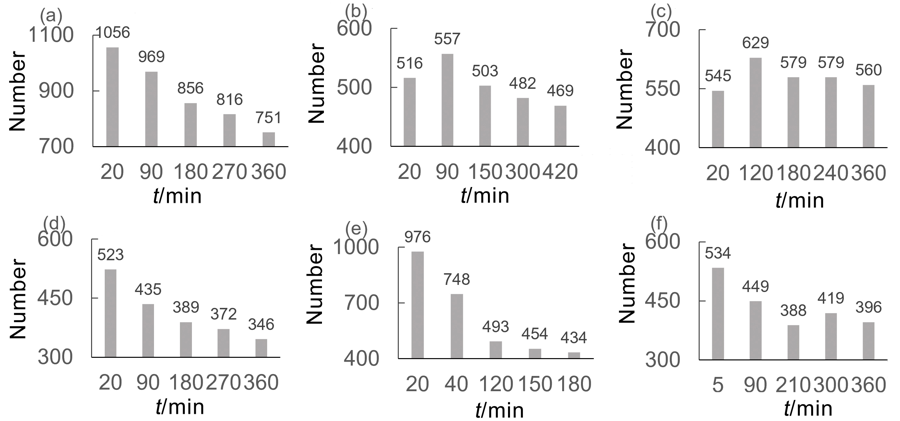
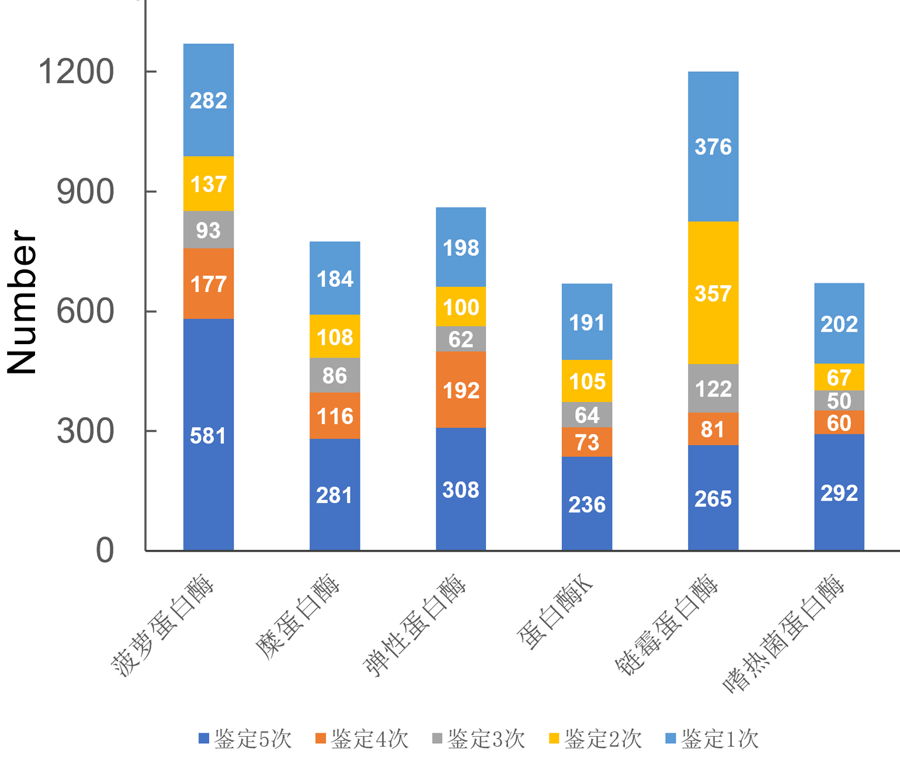
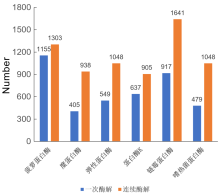
| [1] |
Galat, A. Arch. Biochem. Biophys. 1999, 371,149.
pmid: 10545201
|
| [2] |
Jones, D. T.; Taylor, W. R.; Thornton, J. M. Bioinformatics 1992, 8,275.
doi: 10.1093/bioinformatics/8.3.275
|
| [3] |
Fowler, D. M.; Araya, C. L.; Fleishman, S. J.; Kellogg, E. H.; Stephany, J. J.; Baker, D.; Fields, S. Nat. Methods 2010, 7,741.
doi: 10.1038/nmeth.1492
|
| [4] |
Beck, A.; Sanglier-CianféRani, S.; Van Dorsselaer, A. Anal. Chem. 2012, 84,4637.
doi: 10.1021/ac3002885
|
| [5] |
Kelleher, N. L. Anal. Chem. 2004, 76,197.
pmid: 15190879
|
| [6] |
Ge, Y.; Lawhorn, B. G.; Elnaggar, M.; Strauss, E.; Park, J.-H.; Begley, T. P.; Mclafferty, F. W. J. Am. Chem. Soc. 2002, 124,672.
doi: 10.1021/ja011335z
|
| [7] |
Sun, R. X.; Luo, L.; Wu, L.; Wang, R. M.; Zeng, W. F.; Chi, H.; Liu, C.; He, S. M. Anal. Chem. 2016, 88,3082.
doi: 10.1021/acs.analchem.5b03963
|
| [8] |
Seidler, J.; Zinn, N.; Boehm, M. E.; Lehmann, W. D. Proteomics 2010, 10,634.
doi: 10.1002/pmic.200900459
pmid: 19953542
|
| [9] |
Zhang, Y.; Fonslow, B. R.; Shan, B.; Baek, M. C.; Yates, J. R. Chem. Rev. 2013, 113,2343.
doi: 10.1021/cr3003533
|
| [10] |
Liu, X.; Dekker, L. J.M.; Wu, S.; Vanduijn, M. M.; Pevzner, P. A.; Pa, P. J. Proteome Res. 2014, 13,3241.
doi: 10.1021/pr401300m
|
| [11] |
Zhou, Y.; Xiao, Y. Acta Chim. Sinica 2018, 76,177. (in Chinese).
doi: 10.6023/A17110484
|
|
( 周怡青, 肖友利, 化学学报, 2018, 76,177.)
doi: 10.6023/A17110484
|
| [12] |
Tsiatsiani, L.; Heck, A. J. FEBS J. 2015, 282,2612.
doi: 10.1111/febs.2015.282.issue-14
|
| [13] |
Maccoss, M.; Mcdonald, W.; Saraf, A.; Sadygov, R.; Clark, J.; Tasto, J.; Gould, K.; Wolters, D.; Washburn, M.; Weiss, A.; Clark, J.; Yates, J. Proc. Natl. Acad. Sci. U. S. A. 2002,99,7900.
doi: 10.1073/pnas.122231399
|
| [14] |
Xu, T.; Wong, C. C.L.; Kashina, A.; Yates, J. R. Nat. Protoc. 2009, 4,325.
doi: 10.1038/nprot.2008.248
|
| [15] |
Allmer, J. Expert Rev. Proteomic. 2011, 8,645.
doi: 10.1586/epr.11.54
|
| [16] |
Mou, C.; Wang, H.; Zhou, P.; Hou, X. J. Comput. Appl. 2021,1. (in Chinese).
|
|
( 牟长宁, 王海鹏, 周丕宇, 侯鑫行, 计算机应用, 2021,1.)
|
| [17] |
Yang, C.; Liu, J.; Zhang, W.; Shan, Y.; Dai, Z.; Zhang, L.; Zhang, Y. Chin. J. Anal. Chem. 2021, 49,366. (in Chinese).
|
|
( 杨超, 刘健慧, 张玮杰, 单亦初, 戴忠鹏, 张丽华, 张玉奎, 分析化学, 2021, 49,366.)
|
| [18] |
Ma, B.; Zhang, K.; Hendrie, C.; Liang, C.; Li, M.; Doherty‐Kirby, A.; Lajoie, G. Rapid Commun. Mass Spectrom. 2003, 17,2337.
doi: 10.1002/(ISSN)1097-0231
|
| [19] |
Zhang, J.; Xin, L.; Shan, B.; Chen, W.; Xie, M.; Yuen, D.; Zhang, W.; Zhang, Z.; Lajoie, G. A.; Ma, B. Mol. Cell. Proteomics 2012, 11,M111.010587.
|
| [20] |
Chi, H.; Sun, R.-X.; Yang, B.; Song, C.-Q.; Wang, L.-H.; Liu, C.; Fu, Y.; Yuan, Z.-F.; Wang, H.-P.; He, S.-M. J. Proteome Res. 2010, 9,2713.
doi: 10.1021/pr100182k
|
| [21] |
Yang, H.; Chi, H.; Zeng, W.-F.; Zhou, W.-J.; He, S.-M. Bioinformatics 2019, 35,i183.
doi: 10.1093/bioinformatics/btz366
|
| [22] |
Yang, H.; Chi, H.; Zhou, W.-J.; Zeng, W.-F.; He, K.; Liu, C.; Sun, R.-X.; He, S.-M. J. Proteome Res. 2017, 16,645.
doi: 10.1021/acs.jproteome.6b00716
|
| [23] |
Yang, H.; Li, Y.-C.; Zhao, M.-Z.; Wu, F.-L.; Wang, X.; Xiao, W.-D.; Wang, Y.-H.; Zhang, J.-L.; Wang, F.-Q.; Xu, F. Mol. Cell. Proteomics 2019, 18,773.
doi: 10.1074/mcp.TIR118.000918
|
| [24] |
Frank, A.; Pevzner, P. Anal. Chem. 2005, 77,964.
pmid: 15858974
|
| [25] |
Frank, A. M.; Savitski, M. M.; Nielsen, M. L.; Zubarev, R. A.; Pevzner, P. A. J. Proteome Res. 2007, 6,114.
pmid: 17203955
|
| [26] |
Ma, B. J. Am. Soc. Mass Spectrom. 2015, 26,1885.
doi: 10.1007/s13361-015-1204-0
|
| [27] |
Cheng, X.; Yang, X.; Li, J. Genomics and Applied Biology 2020, 39,3431. (in Chinese).
|
|
( 成茜, 杨筱韵, 李婧, 基因组学与应用生物学, 2020, 39,3431.)
|
| [28] |
Muth, T.; Renard, B. Y. Brief. Bioinform. 2018, 19,954.
doi: 10.1093/bib/bbx033
|
| [29] |
Lu, B.; Chen, T. J. Comput. Biol. 2003, 10,1-12s.
|
| [30] |
Savidor, A.; Barzilay, R.; Elinger, D.; Yarden, Y.; Levin, Y. Mol. Cell. Proteomics 2017, 16,1151.
doi: 10.1074/mcp.O116.065417
|
| [31] |
Tran, N. H.; Rahman, M. Z.; He, L.; Xin, L.; Shan, B.; Li, M. Sci. Rep. 2016, 6,1.
doi: 10.1038/s41598-016-0001-8
|
| [32] |
Yang, C.; Liu, J.; Hu, Y.; Dai, Z.; Zhang, Y. J. Sep. Sci. 2020, 43,3665.
doi: 10.1002/jssc.v43.18
|
 ), 张玮杰a,b, 戴忠鹏a, 张丽华a,*(
), 张玮杰a,b, 戴忠鹏a, 张丽华a,*(